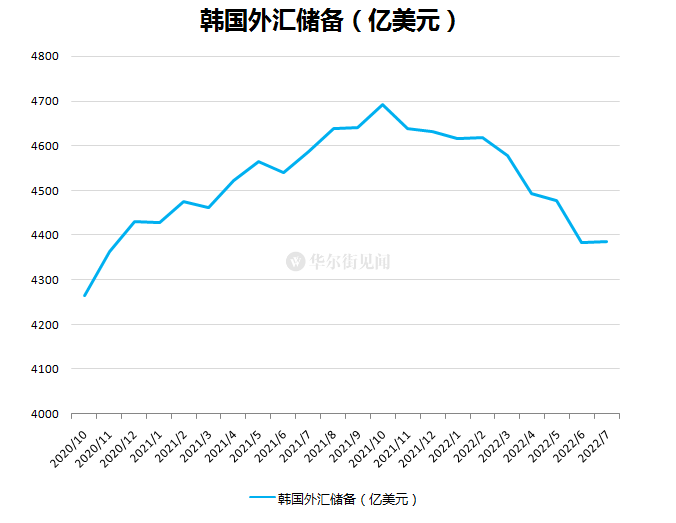
4月2日下午,百度智能芯片总经理欧阳剑在一场公开课中首次对昆仑芯片进行了详细分享,并公开了昆仑K200与英特尔T4 GPU的多项对比数据,其中最有优势的一项数据是Gemm-Int8 的Benchmark是T4性能的3倍。欧阳剑还通过视频展示了昆仑芯片的杀手锏,与国产处理器飞腾的良好适配。
2018年的百度AI开发者大会上,百度创始人、董事长兼CEO李彦宏宣布推出自研AI芯片昆仑。百度研发AI芯片的积累得益于其用FPGA做AI加速的积累,也得益于其在软件定义加速器和XPU架构的多年积累。
百度最早在2010年开始用FPGA做AI架构的研发,2011年开展小规模部署上线,2017年部署超过了10000片FPGA,2018年发布自主研发AI芯片,2019年下半年流片成功,2020年开始量产。
昆仑芯片的定位是通用AI芯片,目标是提供高性能、低成本、高灵活性的AI芯片。欧阳剑在分享中说:“相比GPU,昆仑芯片的通用性和可编程性都做的不错,并且我们还在努力把编程性做的更好。”
昆仑发布之后,其相关消息陆续公布。架构方面,昆仑有2个计算单元,512GB/S的内存带宽,16MB SRAM/unit。欧阳剑介绍,16MB的SRAM对AI推理很有帮助,XPU架构上的XPU-SDNN是为Tensor等而设计,XPU-Cluster则能够满足通用处理的需求。
昆仑第一代芯片并没有采用NVLink,而是通过PCIE 4.0接口进行互联。在三星14nm的制造工艺和2.5D封装的支持下,昆仑芯片峰值性能可以达到260TOPS,功耗为150W。
在灵活性和易用性方面,昆仑面向开发者提供类似英伟达CUDA的软件栈,可以通过C/C++语言进行编程,降低开发者的开发难度。
目前,基于第一代昆仑芯片,百度推出了两款AI加速卡,K100和K200,前者算力和功耗都是后者的两倍。
在今天的分享中,欧阳剑给出了一系列K200对比英伟达T4的数据,其中在Gemm-Int8数据类型,4K X 4K的矩阵下,昆仑K200的Benchmark分出超过2000,是英伟达T4的3倍多。
在语音常用的Bert/Ernie测试模型下,昆仑也有明显性能优势。
在线上性能数据的表现上,昆仑的表现相比英伟达T4更加稳定,且延迟也有优势。
在图像分割YOLOV3算法中,昆仑虽然有优势,但优势已经不那么明显。不过欧阳剑表示百度仍然在通过持续的优化提高昆仑的性能。
他同时表示,昆仑已经在百度内部规模应用。至于对外提供AI算力,去年12月13日百度通过定向邀请的方式通过百度云提供昆仑的算力。在与欧阳剑的直播互动中,雷锋网(公众号:雷锋网)了解到通过百度云提供昆仑AI算力目前仍然是定向邀请的方式,且主要是私有部署的方式。百度会通过定向邀请的客户的反馈消息,再通过百度云大规模向外提供昆仑的算力,但他没有给出具体的时间线。
除了通过百度云提供昆仑的算力,欧阳剑也展示了昆仑加速卡在工业智能设备中的应用。欧阳剑演示的是用CPU和昆仑加速卡去进行产品缺陷检测,昆仑可以大幅提升速度,但并没有给出具体的对比数据。
另外一个展示则是昆仑的杀手锏,那就是和国产处理器平台飞腾的适配。在2019飞腾生态伙伴大会上,欧阳剑就透露昆仑AI芯片正在适配国产飞腾服务器,做性能调优工作。在今天的线上分享中,欧阳剑展示了采用昆仑加速卡带来的图像分割速度的显著加速。
飞腾CPU处理器采用的是Armv8指令级,主要用在数据中心和云计算中心,作为国产芯的代表,昆仑选择与飞腾进行很好地适配显然是看中了国产自研芯片的大市场。
通过飞腾CPU+昆仑AI加速器的方式,双方可以更好的实现国产芯片在服务器市场的国产化,也可以视为昆仑AI芯片和加速卡未来增长的一个重要动力和杀手锏。
关键词: